AI Agents: What Actually Changes for Insurers' IT Teams
An LLM wrapped in a loop and connected to tools is a new way to build software. This is no longer a POC, and most IT stacks are not ready for it.
People talk about agents everywhere now. In slide decks. In keynotes. In vendor pitches. Everyone wants one now. When I ask what an agent actually is, the answers range from "a smart chatbot" to "something that can do everything on its own."
This article is a snapshot of where things stand: what agents are, what works today, what still breaks, and what all of that means when you run enterprise IT.
What is an agent, in practice?
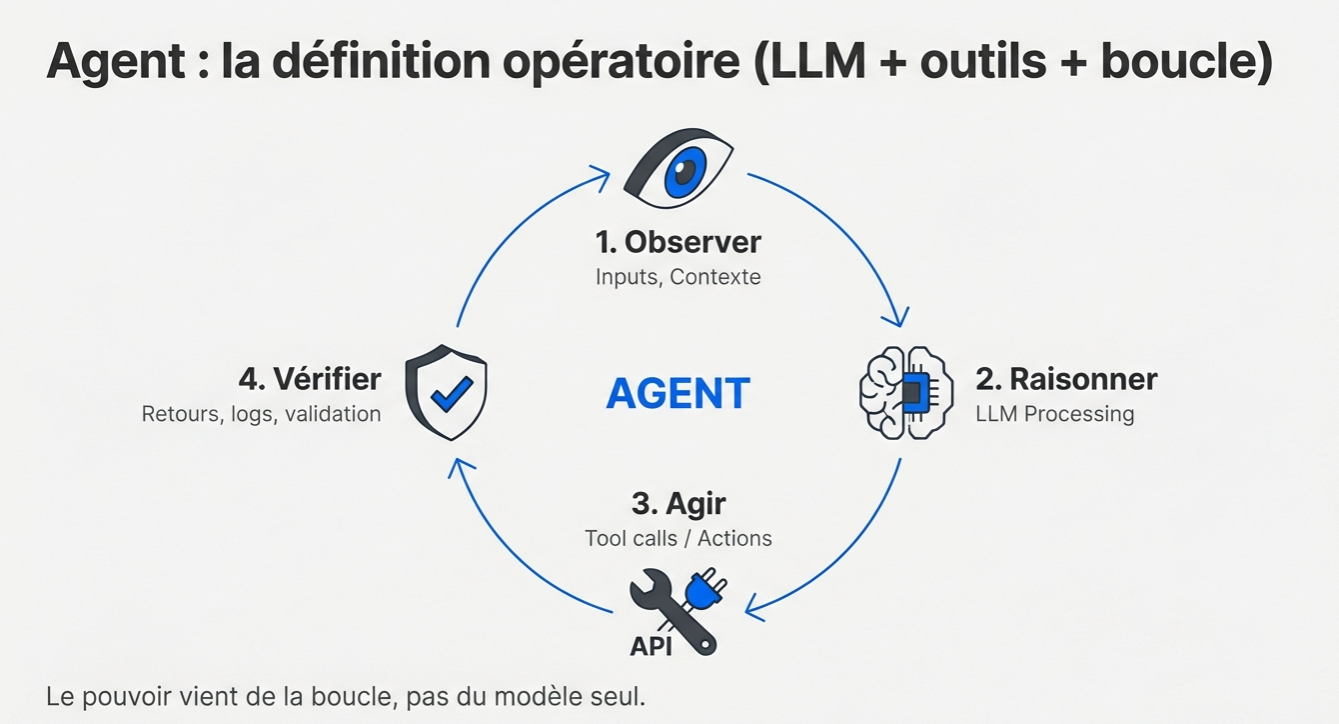
An agent is an LLM that reasons, uses tools, and operates in a loop. The LLM is the reasoning engine. It plans and decides. Around it sits the harness: the tools it can access, the permissions it gets, and the fallback or recovery mechanisms wrapped around it.
The loop looks like this:
- Observe: the agent receives inputs and context.
- Reason: the LLM processes the situation and plans.
- Act: it calls tools and executes actions.
- Verify: it checks the result, validates it, and loops again if needed.
The value comes from the loop itself.
When an agent "calls a tool," what happens under the hood is fairly simple. The LLM emits text that effectively says, "Call tool X with parameters Y." The surrounding code, the harness, intercepts that output, interprets it as a function call, executes it, and sends the result back to the model. Then the loop continues.
Here is the standard agent loop:
flowchart TD
START(["User request"]) --> A
A["Think\nAnalyze context\nPlan the action"] --> B{"Need\na tool?"}
B -->|Yes| D["Act\nCall the right\ntool"]
D --> E["Observe\nAnalyze the result\nUpdate the context"]
E --> A
B -->|No| F(["Final answer"])
style START fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,color:#283593
style A fill:#fff8e1,stroke:#f9a825,stroke-width:2px,color:#4e342e
style B fill:#fce4ec,stroke:#e91e63,stroke-width:2px,color:#880e4f
style D fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px,color:#0d47a1
style E fill:#e8f5e9,stroke:#43a047,stroke-width:2px,color:#1b5e20
style F fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
linkStyle 0 stroke:#5c6bc0,stroke-width:2px
linkStyle 1 stroke:#1e88e5,stroke-width:2px
linkStyle 2 stroke:#43a047,stroke-width:2px
linkStyle 3 stroke:#f9a825,stroke-width:2px
linkStyle 4 stroke:#e91e63,stroke-width:2px
Take a concrete insurance example: an agent answering a question about a claim.
sequenceDiagram
participant U as 👤 User
participant A as 🤖 AI Agent
participant T as 🔧 Tools
U->>A: "What is the status of claim #4521?"
Note right of A: 🧠 I need to fetch claim data
A->>T: get_claim_details(id=4521)
T-->>A: { status: "in progress", amount: 15000€, docs: 3 }
Note right of A: 🧠 The customer has 3 documents, let's verify
A->>T: get_documents(claim_id=4521)
T-->>A: [expert_report, invoice, photo]
Note right of A: ✅ I have what I need
A-->>U: Claim #4521 is in progress. 15,000€. 3 documents received.
The agent is not following a fixed script. At each step, it decides what to do next based on what it just observed.
Another category worth calling out is the computer-using agent, or CUA (Computer Using Agent). In that setup, the agent does not go through APIs. It watches the interface itself and acts on it. It gets a screenshot, decides where to click, moves the mouse, captures another screenshot, and clicks again. If you have clean APIs, you can usually avoid that. But in legacy environments, where old systems expose neither APIs nor connectors, CUA opens doors that used to stay shut: question answering over business apps, data entry in old interfaces, and testing on inherited systems.
One problem shows up immediately: the vocabulary has gone soft. Assistants, copilots, agents, autonomous agents, tool-using chatbots. The boundaries have blurred. Vendors label things as agents when they still look a lot like upgraded assistants. Before going any further, it helps to clear that up.
In practice, two axes matter: whether the agent works in the background while you do something else, and how much autonomy it has before it needs approval. An "assistant" making decisions in the background is an agent. An "agent" that only answers questions is really an assistant. The label does not matter much. What matters is the scope it actually has to act.
The trend: agents can stay on task for longer
Before talking about task endurance, one point is worth stating plainly: an agent does not stay on task longer just because the model reasons better. It lasts longer because it can hold its context together.
That is where the context window comes in. A context window is the amount of information a model can take into account at one time: the initial instruction, the conversation history, tool outputs, open documents, intermediate notes. As long as everything that matters fits within that window, the agent stays coherent. Once the window fills up, the model starts compressing, forgetting, or drifting.
So task endurance is tied to that limit. The longer the task, the more context piles up: hypotheses, failed attempts, errors, tool outputs, intermediate decisions. If the agent cannot manage that mass of information well, it loses the thread. The issue is not always raw intelligence. Often it is operational memory.
What is changing now is not just the raw size of context windows. It is how they are managed: intermediate summaries, better selection of what matters, external memory, compression strategies, and smarter reloading of relevant history. Modern agent endurance comes from that combination: larger context windows and smarter decisions about what goes into them.
That is why the real question is no longer just, "Does the model answer well?" It is, "How long does it stay reliable on a real task?"
Classic benchmarks are flattening out. Models gain fractions of a point on academic tests. One of the most useful metrics now comes from METR: how long a coding agent can work independently on a task.
According to METR:
"We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks."
That task horizon has been doubling roughly every seven months. Claude Opus 4.5 managed five straight hours on a task. Since then, METR says Opus 4.6 has already passed ten hours. If that trend holds, agents that can push through multi-day tasks without interruption will arrive before the decade is out.
Another benchmark matters: GDPEval, a human evaluation that compares model outputs with those of professionals on real knowledge-work tasks such as presentations, spreadsheets, and analysis. Recent models score around 71% on that test. In 71% of cases, human experts judge the model's output to be as good as or better than a professional's. The previous generation sat at 39%.
We are still talking about the first generation of agents: the one built on LLMs. These are language models with a kind of amnesia, and I will come back to that point. The next generations will be smaller, faster, and, above all, better able to learn from experience. We are not there yet.
The Memento problem: memory is still broken
Current agents have a memory problem.
An LLM agent can reason well, but it does not have persistent memory in any meaningful sense. Its context window may be large, but its memory is volatile. Once too much information accumulates, it starts to forget and wobble.
If you want a model to "learn," you still have to retrain it. First comes pretraining: feed it massive amounts of data so it learns to predict the next token. Then comes reinforcement learning: let it reason, try, fail, and reward it when it gets things right. That is where today's reasoning models come from, models that can sustain longer chains of thought.
But all of that requires huge GPU clusters and weeks of compute. Each retraining cycle also risks making the model forget part of what it already knew.
What we would really need is continual learning: the ability to learn incrementally, the way humans do. Our neurons change, our connections shift, and we consolidate experience through repetition and reflection. LLMs still cannot do that in any robust way.
So we work around it. The workaround is a lot like the logic of Memento.
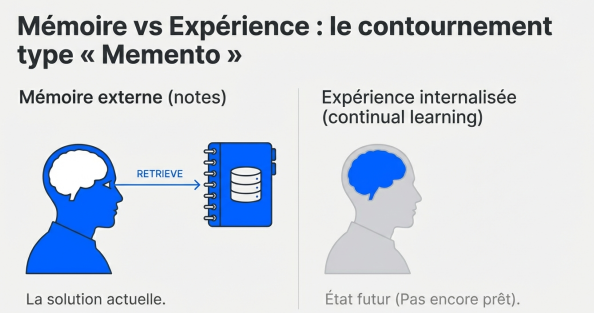
The main character in Memento has anterograde amnesia. He cannot retain new memories, so he tattoos reminders on himself and writes index cards. Every morning, he rereads his notes to remember who he is and what he is trying to do.
LLMs do something similar. What we currently call "memory" in agents, semantic memory, files, databases, is really a patch. The LLM writes notes about you. The next time it talks to you, we tell it: you remember nothing, but go read your notes. It retrieves them, loads them back into context, and acts as if it remembers.
It works, but it is still a workaround.
Imagine a human with a one-hour attention span. After that, everything is gone. That is what agents look like today. We compensate with context compression and recall mechanisms, but the underlying problem remains. An agent's endurance depends as much on operational memory as on raw compute.
Enterprise data: work on the context, not the model
The question comes up all the time: should we train our own models?
Probably not.
Existing models already contain enough general knowledge to cover a wide range of tasks. The leverage is not in the model itself. It is in everything around it: the context.
That is context engineering: giving the agent the right information at the right moment and in the right format. We are even starting to hear the phrase context graph, meaning a structured map of the knowledge the agent can access.
Take an insurance example. If you want an agent to assess a claim file, you do not need to retrain a model. You need to give it what it could not have seen during training: portfolio-specific cases, precedents, operating rules, and the specific quirks of the insured risk.
It is like hiring a junior claims handler. They know the basics, but to make a sound decision they look up similar files and ask senior colleagues how they handled them.
The agent does the same thing. You organize the company's knowledge, make it accessible, and the agent pulls what it needs.
There is a second route as well: experience distillation. As the agent makes decisions, it can keep its own notes. "For this type of file, I relied on that precedent and used this line of reasoning." The next time it sees a similar case, it reads those notes. It does not internalize them into its parameters. It takes notes, like a competent professional who keeps a notebook.
That works surprisingly well. Over time, those notes form a new knowledge layer: the equivalent of a shared lessons-learned system inside a company, where experience compounds instead of disappearing.
Longer term, we will probably see some form of continuous learning: agents that can update part of their weights locally, a kind of artificial neuroplasticity. Right now, the pragmatic path is context.
Coding agents: the first use case that really works
Coding agents are the first agent use case that really works. Not just as demos. In production. They are already changing how developers work day to day.
Code works well for two reasons:
- The people building these agents know the domain. The teams building coding agents are developers. They understand the problems intimately.
- We found a trainable signal that can be verified. Code has one major advantage: you can check automatically whether it works. The agent writes code, runs it, looks at the compiler or test output, fixes it, and tries again. It can iterate on problems with verifiable feedback. GitHub, Stack Overflow, billions of lines of code, plus the issues and fixes around them. That is rich training material.
Claude Code is a good illustration of the shift: a terminal, a programming agent, and commands running directly on your machine. You talk to it, it writes code, and it fixes code.
The key change is access to the real environment. ChatGPT and Perplexity live inside SaaS interfaces disconnected from your actual world. Coding agents interact with your files and your terminal. They change your real environment.
We are already seeing developers orchestrate five agents across five features in parallel, with a supervising agent coordinating the work. That is compound engineering: an engineer who spends less time typing code and more time orchestrating work. In my own network, one startup closed a two-month sprint on a roadmap that had originally been planned over twelve months. On my side, when I need a simple application, I can now build it in an hour.
If compound engineering works for software, compound business will follow.
An actuary orchestrating risk-analysis agents. A claims manager orchestrating assessment and pricing agents. The pattern is the same: the human expert pilots the intelligence.
Workflows vs. agents: pick the right battle
What happens to workflows and RPA in an agent world?
The agent should not sit inside a workflow. It should sit above it. It should call workflows the way it calls any other tool.
The strength of an agent is its non-determinism, its ability to adapt when something does not happen the way you expected. Suppose a bank-account extraction workflow fails because the scanned page is upside down. The agent calls an image-rotation tool, reruns OCR, and gets the information back. A rigid workflow simply fails and waits for a human.
The real question is what belongs in deterministic systems, meaning the processes you want to lock down and the non-negotiable business rules, and what belongs in non-deterministic systems, meaning intelligent adaptation to edge cases and surprises. Those two layers should work together, not trap each other.
The operating model around agents should not be a rigid process that dictates which agent calls which other agent in what order. It should be a system that can self-organize.
Preparing IT: foundations for the agent era
This is going to hit enterprise IT. What you need is not a total rewrite. They are layers you add on top of what already exists.
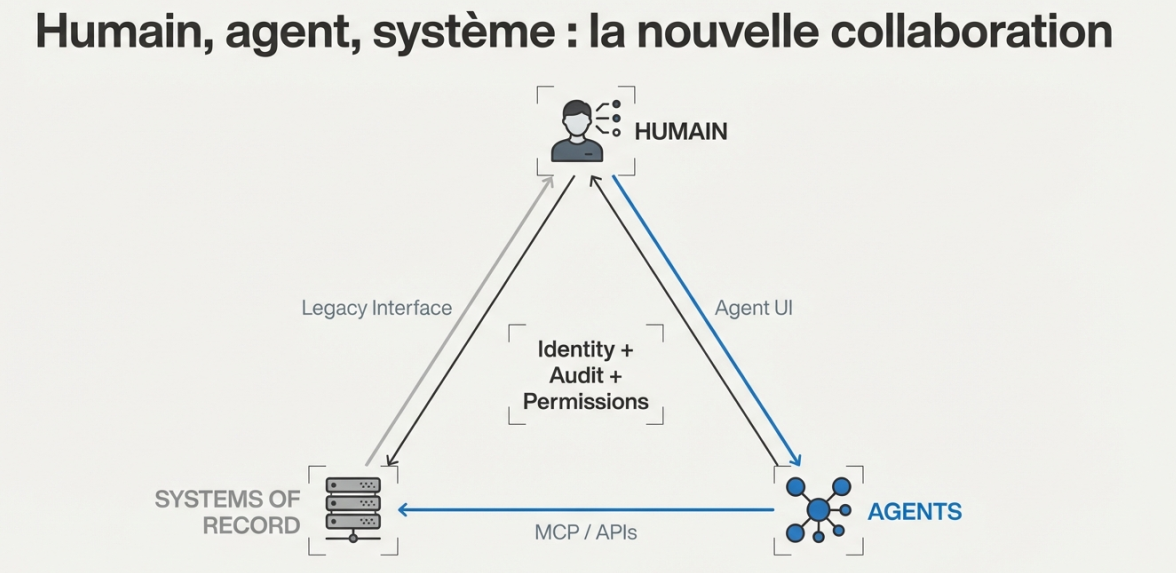
Make the IT stack legible and composable
The new layer sits above the existing estate. Agents will live on top of current systems of record: the ERP, CRM, and business databases already in place. They will call into them and use them. That is their environment.
The IT stack has to be accessible through primitives that an agent can compose. Not a patchwork of overlapping APIs with inconsistent granularity, such as one API for all claims and another just for windshield claims. What you need is an intermediate access layer that makes the system legible and documented for humans and agents alike.
Building that access layer progressively, through APIs and MCP (Model Context Protocol), makes the application estate usable by agents. MCP makes the IT stack accessible to agents. The protocol itself will evolve, and it may well be replaced. That is not the important part. Coherence and documentation are. Well-designed APIs already take you a long way.
Govern, trace, audit
Every agent action needs to be traceable. Which agent did what, when, and at whose request? You need an audit system that makes agent actions as readable as human actions. In a regulated sector like insurance, that is not optional.
Manage non-human identities
Agents need identities of their own, not shared user accounts. Identities with rights, boundaries, and explicit autonomy scopes. Two years ago, this governance topic barely existed. Now it is real.
From the application layer to the cognitive layer
We are still early, roughly where the internet was before stacks stabilized. We had LAMP (Linux, Apache, MySQL, PHP), then MEAN (MongoDB, Express, Angular, Node), then MERN (MongoDB, Express, React, Node), then MEVN (MongoDB, Express, Vue, Node). The agent world will follow the same path: an agentic stack will emerge over time, covering how agents are built, how they run in production, how they are supervised, and what good practice looks like. It is still early. Other patterns will emerge.
What is starting to take shape:
- Agent ↔ Agent: communication protocols. Maybe natural language at first. Maybe more compact formats later between compatible agents. Agents from the same generation will probably exchange information more efficiently than they can through plain text alone.
- Agent ↔ Human: ephemeral interfaces generated on the fly. The agent decides how to present information, as a list, a table, or a chart, depending on the content and the user's preferences. Protocols such as Agent UI are already appearing.
- Agent ↔ Backend: MCP (Model Context Protocol), which standardizes access to tools, data, and services. It is emerging as the de facto standard.
We are moving from an application layer to a cognitive layer. The primary building blocks are no longer applications. They are agents interacting with one another and with the systems of record underneath.
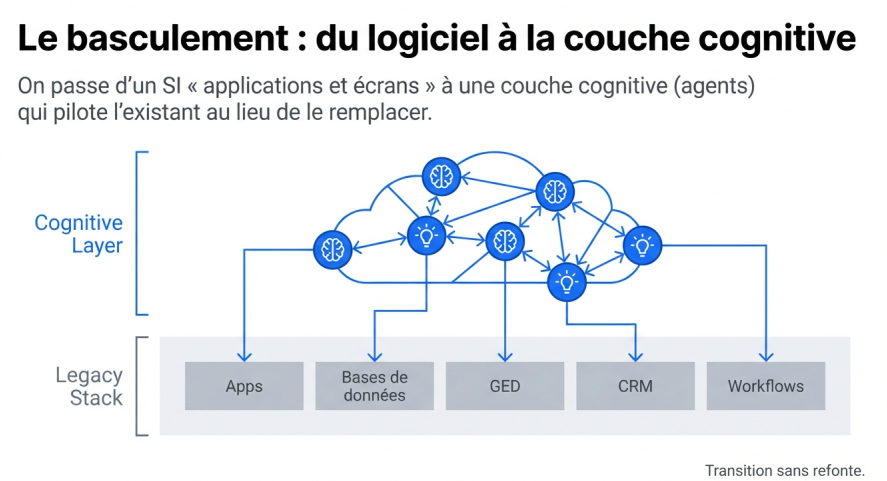
Systems of record are not disappearing. They become the persistence layer: stable, deterministic databases with fixed schemas. You do not replace them. They remain the foundation. The agent works with temporary artifacts, such as files, notes, and context memory, and communicates through standardized protocols.
This will normalize and become the next version of software, with its own good practices. We are not there yet.
Insurance: a natural fit for agents
Insurance is fertile ground for agents. It is an information-heavy business: every claim is unique, every file requires its own analysis, and every decision draws on a different mix of rules and precedents. That is exactly the kind of work where RPA hit a wall, because deterministic engines struggle with that uniqueness. Every insurer has its own specifics and its own edge cases.
Agents adapt. They read, reason, and adjust to the context of each file. The impact ranges from operational efficiency, by automating time-consuming work, to augmented claims handling, by helping handlers make better decisions, to faster output in pricing, product design, and risk analysis.
Insurance also has a loop that fits this model naturally. A claim is the point where risk meets reality. Every file becomes a source of learning. Pricing and product design can then adapt to that reality. Delivering the service and learning from the field is what drives long-term profitability. That is the agent loop.
Customer portals will change as well. Insurers spend serious budget and energy on them, but their long-term future is now an open question. Tomorrow, a customer's personal assistant will connect to an insurer's APIs to fetch a certificate or start a claim without going through a web portal at all. More concretely, when I recently wanted to buy car insurance, what I really wanted was an assistant that could compare offers through APIs and negotiate directly, without a comparison platform in the middle. That is where things are heading. Thinking agent-first about distribution is the right question.
What matters most
An agent is intelligence in a loop, connected to tools. Task horizons are getting longer. Protocols are starting to consolidate. This is moving fast.
For IT leaders, the point is not to launch a giant rewrite. It is to make the IT stack legible and composable, to trace what agents do, and to manage their identities the same way you manage human identities.
The organizations building an agent strategy now will turn it into a differentiated asset. The others will wait until everyone has the same tools, the same capabilities, and no room left for differentiation.
Differentiation will come from the knowledge you put inside your agents.
Note: this article draws on my experience as a Chief Data and AI Officer in the insurance sector and on many conversations with CIOs and AI experts. The views expressed here are personal.
Want to discuss it? Reach out on LinkedIn or by email at contact@arioua.tech.