Agents IA : ce qui change vraiment pour le SI des assureurs
Un LLM dans une boucle, avec des outils : une nouvelle façon de faire du logiciel. Ce n'est plus un POC. Et votre SI n'est pas prêt.
On parle d'agents partout. Dans les slides, dans les keynotes. Tout le monde en veut. Quand je demande "c'est quoi un agent pour toi ?", les réponses varient entre "un chatbot intelligent" et "un truc qui fait tout, tout seul".
Ce qui suit est un état des lieux : ce que sont les agents, ce qui marche, ce qui coince, et ce que ça implique quand on gère un SI.
Qu'est-ce qu'un agent, concrètement ?
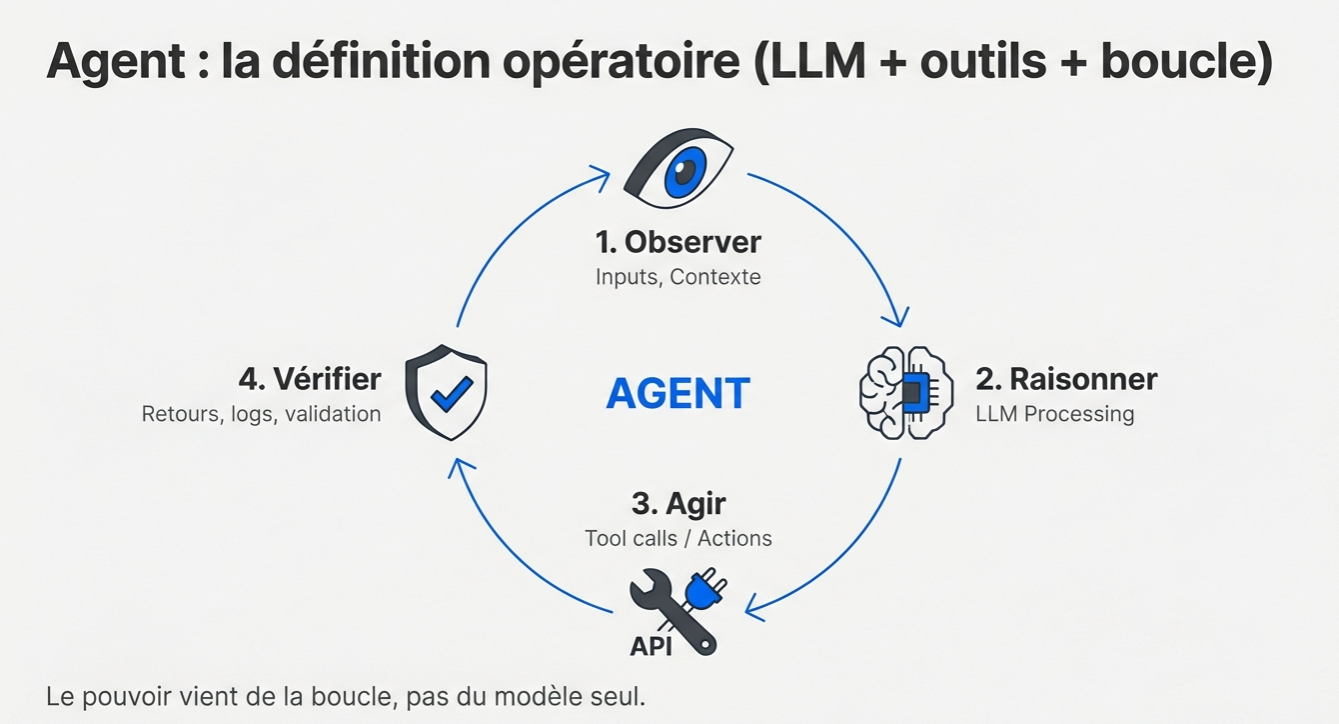
Un agent : un LLM qui raisonne, utilise des outils, et opère en boucle. Le LLM (Large Language Model) est le cerveau. Il planifie et il décide. Autour, il y a le harness : les outils accessibles, les autorisations, les mécanismes de rattrapage et de repli.
La boucle, c'est ça :
- Observer : l'agent reçoit des inputs, du contexte
- Raisonner : le LLM traite, planifie
- Agir : il appelle des outils, exécute des actions
- Vérifier : il vérifie les retours, valide, et recommence si nécessaire
La valeur vient de la boucle.
Quand l'agent "appelle un outil", ce qui se passe en coulisses est simple : le LLM génère du texte qui dit "je veux appeler l'outil X avec les paramètres Y". Le code autour, le harness, intercepte ce texte, l'interprète comme un appel de fonction, l'exécute, et renvoie le résultat au LLM. Et ça continue.
Voici la boucle typique d'un agent :
flowchart TD
START(["Requête utilisateur"]) --> A
A["Réfléchir\nAnalyser le contexte\nPlanifier l'action"] --> B{"Outil\nnécessaire ?"}
B -->|Oui| D["Agir\nAppeler l'outil\napproprié"]
D --> E["Observer\nAnalyser le résultat\nMettre à jour le contexte"]
E --> A
B -->|Non| F(["Réponse finale"])
style START fill:#e8eaf6,stroke:#5c6bc0,stroke-width:2px,color:#283593
style A fill:#fff8e1,stroke:#f9a825,stroke-width:2px,color:#4e342e
style B fill:#fce4ec,stroke:#e91e63,stroke-width:2px,color:#880e4f
style D fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px,color:#0d47a1
style E fill:#e8f5e9,stroke:#43a047,stroke-width:2px,color:#1b5e20
style F fill:#f3e5f5,stroke:#8e24aa,stroke-width:2px,color:#4a148c
linkStyle 0 stroke:#5c6bc0,stroke-width:2px
linkStyle 1 stroke:#1e88e5,stroke-width:2px
linkStyle 2 stroke:#43a047,stroke-width:2px
linkStyle 3 stroke:#f9a825,stroke-width:2px
linkStyle 4 stroke:#e91e63,stroke-width:2px
Prenons un exemple concret dans l'assurance. Un agent chargé de répondre à une question sur un sinistre :
sequenceDiagram
participant U as 👤 Utilisateur
participant A as 🤖 Agent IA
participant T as 🔧 Outils
U->>A: "Quel est le statut du sinistre #4521 ?"
Note right of A: 🧠 Je dois chercher les infos du sinistre
A->>T: get_sinistre_detail(id=4521)
T-->>A: { statut: "en cours", montant: 15000€, docs: 3 }
Note right of A: 🧠 Le client a 3 documents, vérifions
A->>T: get_documents(sinistre_id=4521)
T-->>A: [rapport_expert, facture, photo]
Note right of A: ✅ J'ai tout ce qu'il faut
A-->>U: Sinistre #4521 en cours. 15 000€. 3 pièces reçues.
L'agent ne suit pas un script. Il décide à chaque étape quoi faire, selon ce qu'il a observé.
Une autre catégorie à connaître : le CUA (Computer Using Agent). Là, l'agent ne passe pas par des API, il observe l'interface graphique directement et agit dessus. Il reçoit un screenshot, décide où cliquer, bouge la souris, reprend un screenshot, reclique. On peut toujours s'en passer quand on a des API propres. Mais dans des situations de legacy, des systèmes anciens sans API, sans connecteurs, le CUA permet d'automatiser ce qu'on ne pouvait pas avant : du Q&A sur des applications métier, des process de saisie, du test sur des interfaces héritées.
À ce stade, une difficulté apparaît : le vocabulaire est devenu flou. Entre assistants, copilotes, agents, agents autonomes ou simples chatbots outillés, les frontières sont brouillées. Les éditeurs appellent souvent "agent" ce qui ressemble surtout à un assistant amélioré. Avant d'aller plus loin, il faut donc clarifier cette confusion.
Ce qui compte en pratique, ce sont deux axes : la synchronicité (l'agent travaille-t-il pendant que l'utilisateur fait autre chose ?) et l'autonomie (jusqu'où va-t-il sans demander la permission ?). Un "assistant" qui prend des décisions en arrière-plan, c'est un agent. Un "agent" qui ne fait que répondre, c'est un assistant. Le périmètre d'action définit ce qu'il est, pas le label.
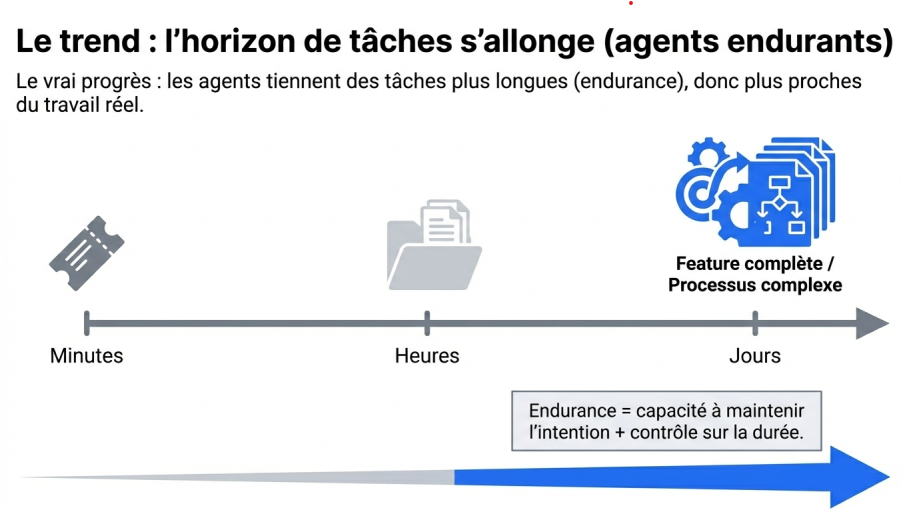
Le trend : des agents de plus en plus endurants
Avant de parler d'endurance, il faut rappeler un point simple : un agent ne "tient" pas longtemps seulement parce que le modèle raisonne bien. Il tient parce qu'il arrive à garder le fil de la tâche.
C'est là qu'intervient la fenêtre de contexte. La fenêtre de contexte, c'est la quantité d'information qu'un modèle peut prendre en compte à un instant donné : la consigne initiale, l'historique de la conversation, les résultats d'outils, les documents ouverts, les notes intermédiaires. Tant que tout ce qui compte tient dans cette fenêtre, l'agent reste cohérent. Quand elle sature, il compresse, oublie, ou commence à dériver.
L'endurance est donc liée à cette limite. Plus une tâche dure, plus elle accumule de contexte : hypothèses, essais, erreurs, sorties d'outils, décisions intermédiaires. Si l'agent ne sait pas bien gérer cette masse d'information, il perd le fil. Il ne manque pas forcément d'intelligence ; il manque de mémoire opérationnelle.
Ce qui change aujourd'hui, ce n'est pas seulement la taille brute des fenêtres de contexte. C'est aussi la manière de les gérer : résumés intermédiaires, sélection plus fine des informations utiles, mémoire externe, stratégies de compression, et rechargement plus intelligent de l'historique pertinent. L'endurance moderne vient de cette combinaison : des fenêtres plus longues et une meilleure gestion de ce qu'on y met.
C'est précisément pour cela que la question n'est plus seulement "est-ce que le modèle répond bien ?", mais "combien de temps reste-t-il fiable sur une tâche réelle ?".
Les benchmarks classiques saturent. Les modèles gagnent des fractions de points sur des tests académiques. L'indicateur qui compte maintenant, c'est METR, qui mesure combien de temps un agent de codage peut travailler seul sur une tâche.
Selon METR :
"We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks."
L'horizon de tâche double tous les 7 mois. Claude Opus 4.5 a travaillé pendant 5 heures d'affilée sur une tâche (depuis, la mise à jour METR indique qu'Opus 4.6 tient désormais plus de 10 heures). Si la tendance tient, d'ici la fin de la décennie, des agents mèneront des tâches de plusieurs jours sans interruption.
Un autre benchmark important : GDPEval, une évaluation humaine qui compare les sorties des modèles à celles de professionnels sur des tâches de travail intellectuel réel (présentations, tableurs, analyses). Les derniers modèles atteignent environ 71% sur ce test. Dans 71% des cas, les experts humains jugent que le résultat du modèle est aussi bon ou meilleur que celui d'un professionnel. La version précédente était à 39%.
On parle de la première génération d'agents, celle basée sur des LLMs, des modèles de langage qui souffrent d'une forme d'amnésie (j'y reviens). Les prochaines générations seront plus compactes et plus rapides. Surtout, elles apprendront de leur expérience. Ce qu'on n'a pas encore.
Le syndrome Memento : le problème de la mémoire
Les agents actuels ont un problème de mémoire.
Un agent LLM raisonne bien, mais il oublie tout. Sa fenêtre de contexte est large, mais sa mémoire est volatile. Au-delà d'un certain volume, il oublie et déraille.
Pour "faire apprendre" un LLM, il faut le ré-entraîner. D'abord le pré-entraînement : on lui fournit des quantités massives de données pour qu'il apprenne à prédire le prochain mot. Ensuite, l'entraînement par renforcement : on le laisse raisonner, essayer, se tromper, et on le récompense quand il réussit. C'est de là que viennent les thinking models, ces modèles qui déroulent leur chaîne de pensée.
Mais tout ça nécessite des GPU massifs et des semaines de calcul. À chaque ré-entraînement, on risque de lui faire oublier ce qu'il savait.
Ce dont on aurait besoin, c'est du continual learning : la capacité d'apprendre de façon incrémentale, comme un humain. Nos neurones changent, nos connexions se modifient, on consolide par l'auto-réflexion. Les LLMs ne savent pas encore faire ça.
Alors on contourne. Le contournement ressemble au film Memento.
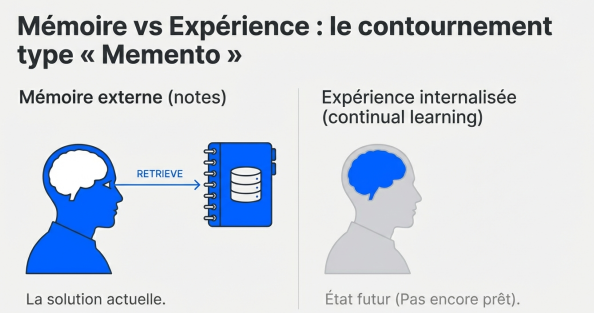
Le personnage de Memento souffre d'amnésie antérograde. Il ne retient rien. Alors il se tatoue des rappels et s'écrit des fiches. Chaque matin, il relit ses notes pour savoir qui il est et ce qu'il doit faire.
Les LLMs font pareil. Les solutions de "mémoire" qu'on voit (mémoire sémantique, fichiers, bases de données), c'est du patch. Le LLM écrit des notes sur toi. La prochaine fois qu'il te parle, on lui dit : "tu ne te rappelles de rien, mais va chercher dans tes notes". Il les récupère, les charge dans son contexte, et fait comme s'il se souvenait.
Ça fonctionne, mais ça reste un contournement.
Imagine un humain avec une fenêtre de concentration d'une heure. Passé ce délai, il oublie tout. C'est un agent aujourd'hui. On compense avec de la compression de contexte et des mécanismes de rappel, mais le problème reste entier. L'endurance des agents est autant une question de mémoire opérationnelle que de puissance de calcul.
La data de l'entreprise : travailler le contexte, pas le cerveau
La question revient souvent : faut-il entraîner ses propres modèles ?
Probablement pas.
Les modèles existants ont consolidé assez de connaissances pour couvrir un large spectre. Le levier, c'est ce qu'il y a autour du cerveau : le contexte.
C'est le context engineering : fournir à l'agent les bonnes informations au bon moment, dans le bon format. On commence même à voir apparaître le concept de context graph, une cartographie structurée de la connaissance accessible à l'agent.
Prenons un exemple dans l'assurance. Si on veut qu'un agent évalue un dossier sinistre, on n'a pas besoin de ré-entraîner un modèle. Il faut lui fournir ce qu'il n'a pas pu voir dans son entraînement : les cas spécifiques du portefeuille, les précédents, les règles de gestion, les particularités du risque couvert.
C'est comme un gestionnaire junior qui rejoint une équipe. Il a les bases, mais pour sécuriser ses décisions, il va chercher dans les dossiers similaires et consulter les retours des seniors.
L'agent fait pareil. On organise la connaissance de l'entreprise, on la rend accessible, et l'agent vient y piocher.
Il y a aussi une deuxième voie : la distillation d'expérience. L'agent, au fil de ses décisions, peut écrire ses propres notes : "pour ce type de dossier, je me suis appuyé sur tel précédent, j'ai utilisé tel raisonnement". La prochaine fois qu'il rencontre un cas similaire, il consulte ses notes. Il ne l'internalise pas dans ses paramètres. Il prend des notes. Comme un professionnel compétent qui tient un carnet.
Ça marche bien. Et au fur et à mesure, ces notes créent une nouvelle couche de connaissance — l'équivalent du REX collectif dans une entreprise, où les collaborateurs partagent leurs expériences pour que les suivants aillent plus vite.
Avec le temps, on verra de l'apprentissage en continu : des agents qui modifient une partie de leurs poids en local, une sorte de neuroplasticité artificielle. Aujourd'hui, la voie pragmatique c'est le contexte.
Les coding agents : le premier cas d'usage qui marche
Les coding agents sont le premier cas d'usage réussi des agents. En production, pas un POC. Ils transforment le quotidien des développeurs.
Le code fonctionne pour deux raisons :
- Les créateurs maîtrisent le sujet. Ceux qui construisent les agents de code sont des développeurs. Ils connaissent par cœur les problèmes qu'ils résolvent.
- On a trouvé un signal d'entraînement vérifiable. Le code a un avantage unique : on peut vérifier automatiquement si ça marche. L'agent écrit du code, l'exécute, regarde le résultat du compilateur, corrige, et recommence. Il peut boucler sur des problèmes dont les solutions sont vérifiables, ce qu'on appelle un verifiable reward. GitHub, Stack Overflow, des milliards de lignes avec leurs problèmes et leurs solutions. L'agent s'amorce sur cette matière.
Le phénomène Claude Code illustre ce qui se passe : un terminal, un agent de programmation qui lance des commandes sur ta machine. Tu parles, il code et il corrige.
Le changement clé : l'accès à l'environnement réel. ChatGPT et Perplexity vivent dans une interface SaaS déconnectée de ta réalité. Les coding agents interagissent avec tes fichiers et ton terminal. Ils modifient ton monde réel.
On commence à voir des développeurs qui orchestrent 5 agents sur 5 fonctionnalités en parallèle, avec un superviseur qui coordonne. C'est le compound engineering : un ingénieur qui ne code plus, il orchestre. Dans mon entourage, une startup a bouclé en deux mois un roadmap planifié sur douze. Moi-même, quand j'ai besoin d'une application, je la développe en une heure.
Si le compound engineering marche pour la programmation, le compound business va suivre.
Un actuaire qui orchestre des agents d'analyse de risque. Un gestionnaire qui orchestre des agents d'évaluation et de chiffrage. Le schéma : l'expert humain pilote l'intelligence.
Workflows vs agents : ne pas se tromper de combat
Quelle place pour les workflows et la RPA dans un monde d'agents ?
L'agent ne doit pas être dans un workflow. Il doit être au-dessus. Il appelle des workflows comme il appelle n'importe quel outil.
La force d'un agent, c'est son indéterminisme, sa capacité à s'adapter quand quelque chose ne se passe pas comme prévu. Un workflow de reconnaissance de RIB se plante parce que la page est à l'envers ? L'agent appelle un outil de rotation, relance l'OCR, et récupère l'information. Un workflow figé, lui, échoue et attend une intervention humaine.
L'enjeu, c'est de savoir ce qui relève du déterminisme (les process qu'on veut figer, les règles métier non négociables) et du non-déterminisme (l'adaptation intelligente face à l'imprévu). Et de ne pas enfermer l'un dans l'autre.
L'organisation autour des agents ne doit pas être un process figé qui dicte quel agent appelle qui dans quel ordre. C'est un système qui s'organise.
Préparer le SI : les fondations pour l'ère des agents
Ça va percuter les systèmes d'information. Les fondations à poser ne sont pas une refonte, mais des couches qui se superposent.
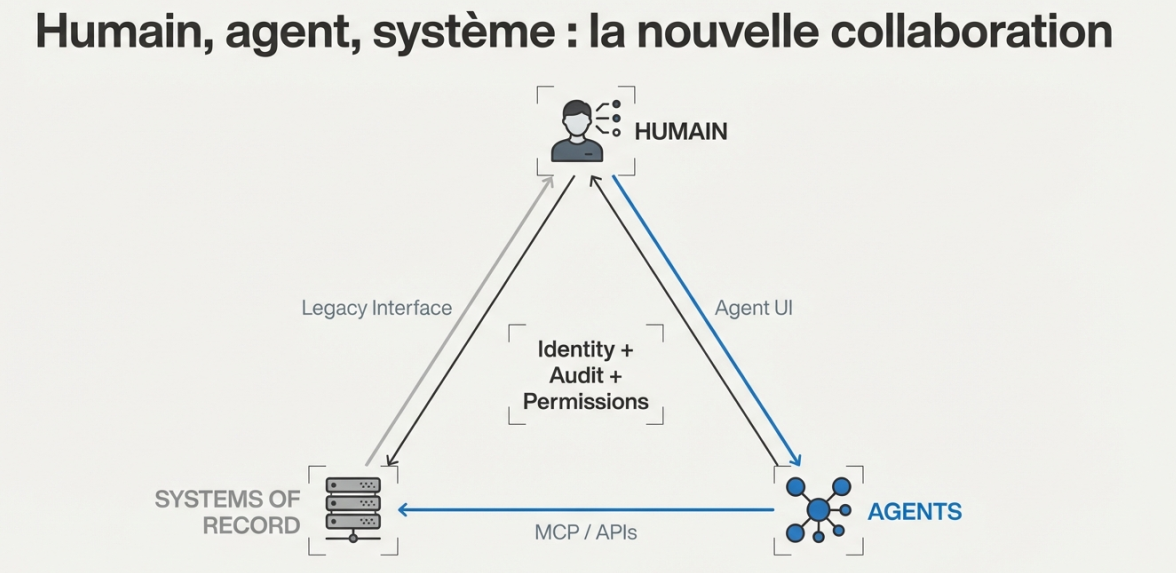
Rendre le SI lisible et composable
La nouvelle couche se pose au-dessus de l'existant. Les agents vont vivre sur les systems of records actuels (les systèmes applicatifs existants : ERP, CRM, bases de données métier). Ils vont les appeler, les utiliser. C'est leur environnement.
Le SI doit être accessible à travers des primitives composables par un agent. Pas des API en doublon avec des niveaux de granularité incohérents (une API pour tous les sinistres, une autre pour les sinistres bris de glace). Une couche intermédiaire qui rend le système d'information lisible et documenté, pour les humains comme pour les agents.
La construction progressive de cette couche d'accès, API et MCP (Model Context Protocol), rend le patrimoine applicatif exploitable. Le MCP rend le SI accessible aux agents. Ce protocole évoluera, voire sera remplacé. Ce qui compte, c'est la cohérence et la documentation de ce qu'on expose. Des API bien pensées suffisent.
Gouverner, tracer, auditer
Chaque action d'agent doit être traçable. Quel agent a fait quoi, quand, sous la demande de qui. Un système d'audit qui rend les actions des agents aussi lisibles que celles des humains. Dans un secteur régulé comme l'assurance, c'est non négociable.
Gérer les identités non-humaines
Les agents ont besoin d'identités propres, pas de comptes partagés. Des identités avec des droits et des périmètres d'autonomie. Ce sujet de gouvernance n'existait pas il y a deux ans.
De la couche applicative à la couche cognitive
On est au début, comme au début d'Internet, avant que les stacks se stabilisent. On a eu LAMP (Linux, Apache, MySQL, PHP), puis MEAN (MongoDB, Express, Angular, Node.js), MERN (MongoDB, Express, React, Node.js), MEVN (MongoDB, Express, Vue, Node.js). Le monde des agents va suivre la même trajectoire : un stack agentique va se consolider, de la construction des agents à leur supervision en production, avec ses standards et ses bonnes pratiques. C'est encore tôt, et d'autres façons de faire vont émerger.
Ce qui se dessine :
- Agent ↔ Agent : des protocoles de communication (Agent-to-Agent). Peut-être en langage naturel au début. Peut-être dans des formats plus compacts entre agents compatibles. Les agents d'une même génération pourront probablement échanger de l'information de façon plus efficace que par du texte.
- Agent ↔ Humain : des interfaces éphémères, générées à la volée. L'agent décide comment afficher l'information (une liste, un tableau, un graphique) selon le contenu et les préférences de l'utilisateur. Des protocoles comme Agent UI émergent déjà.
- Agent ↔ Backend : le MCP (Model Context Protocol) qui standardise l'accès aux outils, aux données, aux services. C'est en train de devenir le standard de fait.
On passe d'une couche applicative à une couche cognitive. Les composants de base ne sont plus des applications mais des agents qui interagissent entre eux, et avec des systems of records (systèmes applicatifs, bases de données) en dessous.
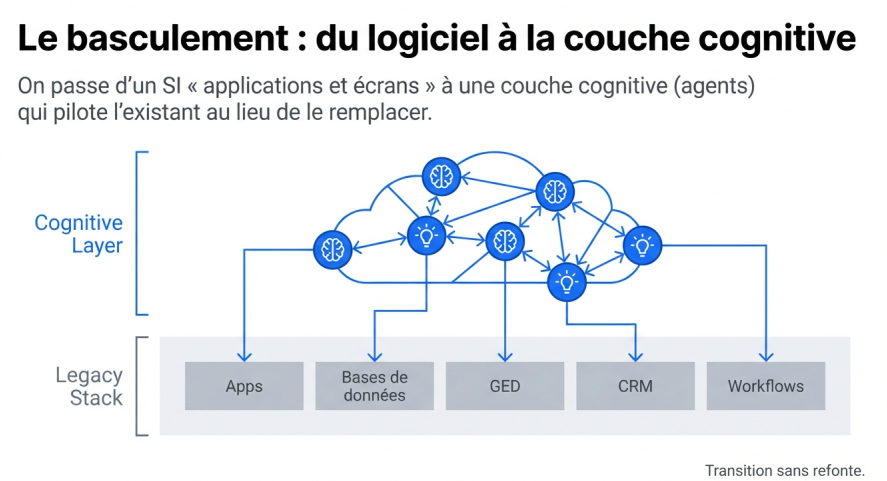
Les systems of records ne disparaissent pas. Ils deviennent la couche de persistance, des bases stables et déterministes avec un schéma fixe. On ne les remplace pas, ils restent le socle. L'agent, lui, crée des artefacts éphémères pour travailler (fichiers, notes, mémoire de contexte) et communique via des protocoles standardisés.
Ça va se normaliser et devenir le nouveau logiciel, avec ses propres bonnes pratiques. On n'y est pas encore.
L'assurance : un terrain naturel pour les agents
L'assurance est un terrain propice pour les agents. C'est un métier intensif en information : chaque sinistre est unique, chaque dossier demande une analyse spécifique, un croisement de règles et de précédents. C'est le type de travail où la RPA a échoué, parce que les moteurs déterministes ne gèrent pas cette unicité. Chaque assureur a ses spécificités et ses cas limites.
Les agents s'adaptent. Ils lisent, raisonnent, s'ajustent au contexte de chaque dossier. L'impact ira de l'efficience opérationnelle (automatiser ce qui prend du temps), à la gestion augmentée (assister les gestionnaires dans leurs décisions), jusqu'à la production accélérée (tarification, conception de produit, analyse de risque).
La boucle naturelle de l'assurance s'y prête : le sinistre est le point de contact, le moment où on rencontre la réalité du risque. Chaque dossier est une source d'apprentissage. Tarification et conception produit s'adaptent à cette réalité. Livrer le service et apprendre du terrain, c'est ce qui nourrit la rentabilité dans la durée. C'est la boucle agentique.
Les espaces clients vont changer aussi. Les assureurs y investissent de l'énergie et du budget, mais l'avenir de ces portails est en question. Demain, l'assistant personnel du client se connectera aux API de l'assureur pour récupérer une attestation ou lancer une déclaration, sans passer par un portail web. Pour l'anecdote : quand j'ai voulu souscrire une assurance auto, j'aurais aimé que mon assistant puisse comparer les offres via des API et négocier, sans plateforme de comparaison. On y viendra. Penser "agent-first" sur la distribution, c'est la bonne question.
Ce qu'il faut retenir
Un agent, c'est une intelligence dans une boucle, avec des outils. Les modèles deviennent plus endurants, les protocoles se consolident. Ça avance vite.
Ce qui compte pour les responsables du SI, ce n'est pas de lancer une refonte. C'est de rendre le SI lisible et composable, de tracer ce que font les agents, et de gérer leurs identités comme on gère celles des humains.
Ceux qui construisent leur stratégie agent maintenant en feront un actif distinctif. Les autres attendront que tout le monde ait les mêmes outils, les mêmes capacités, et zéro différenciation.
La différenciation viendra de la connaissance que vous mettez dans vos agents.
Note : cet article s'appuie sur mon expérience en tant que CDAIO dans le secteur de l'assurance et sur de nombreux échanges avec des DSI et des experts IA. Les vues exprimées sont personnelles.
Envie d'en discuter ? Contactez-moi sur LinkedIn ou par email à contact@arioua.tech.